Deep Dive into xAI's Open-Source X Recommendation Algorithm: From Phoenix Architecture to the For You Feed
Deep Dive into xAI’s Open-Source X Recommendation Algorithm: From Phoenix Architecture to the For You Feed
Overview
In January 2026, xAI open-sourced xai-org/x-algorithm on GitHub — the core recommendation algorithm driving X’s (formerly Twitter) “For You” feed. The repository has since garnered over 20,800 stars and 3,600 forks. Unlike Twitter’s 2023 partial open-source effort (dismissed as “transparency theater”), this release represents a complete architectural rewrite — from a system reliant on hand-crafted rules to an end-to-end ML-driven architecture based on the Grok Transformer model. The system uses a Two-Tower Model for efficient candidate retrieval, a Transformer ranking model with Candidate Isolation attention masking for fine-grained scoring, and a composable Candidate Pipeline framework that orchestrates query hydration, candidate sourcing, filtering, scoring, and selection. This article provides a comprehensive technical analysis covering system architecture, core components, ML model design, key engineering decisions, and industry comparisons.
1. System Architecture: A Five-Layer Recommendation Pipeline
1.1 Design Philosophy: From Rule-Driven to End-to-End Learning
X’s recommendation algorithm underwent a fundamental architectural paradigm shift in 2026. The code Twitter first open-sourced in March 2023 was described by critics as “entangled spaghetti code and manual filters,” relying on complex clusters and heuristic rules where content would take hours to gain distribution through artificial bottlenecks. The new system released in January 2026 — internally codenamed “Phoenix” — eliminated all hand-designed features and most heuristic rules. The core driver of this shift is xAI’s Grok large language model technology stack. The Phoenix architecture directly adopts the same Transformer architecture as Grok, adapted for the recommendation system scenario. This end-to-end approach means the model learns relevance judgments directly from user engagement sequences (likes, replies, retweets, dwell time, etc.) rather than relying on engineer-defined rules. This design choice significantly reduces the complexity of data pipelines and service infrastructure while making the system more adaptive to changing user behavior. According to xAI’s official documentation, the Grok-based Transformer handles “all the heavy lifting” in the system, determining content relevance by understanding user engagement history.
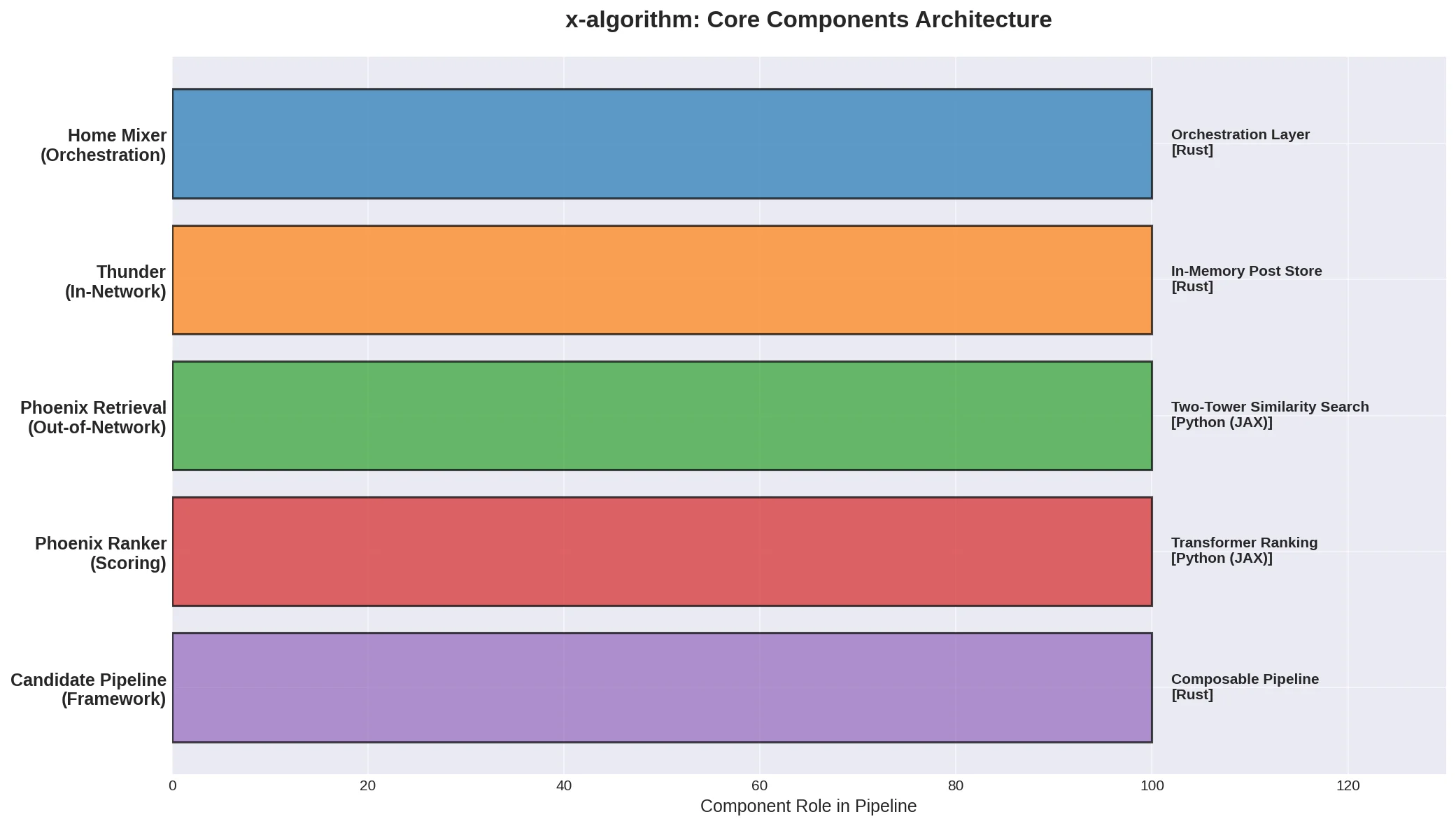
The diagram above shows x-algorithm’s five core components and their roles in the recommendation pipeline. The entire system is written in Rust (57.4%) and Python (42.6%), with the infrastructure layer using Rust for high performance and low latency, and the ML model layer using Python + JAX for flexible deep learning computation.
1.2 Pipeline Execution: Seven-Stage Processing from Request to Response
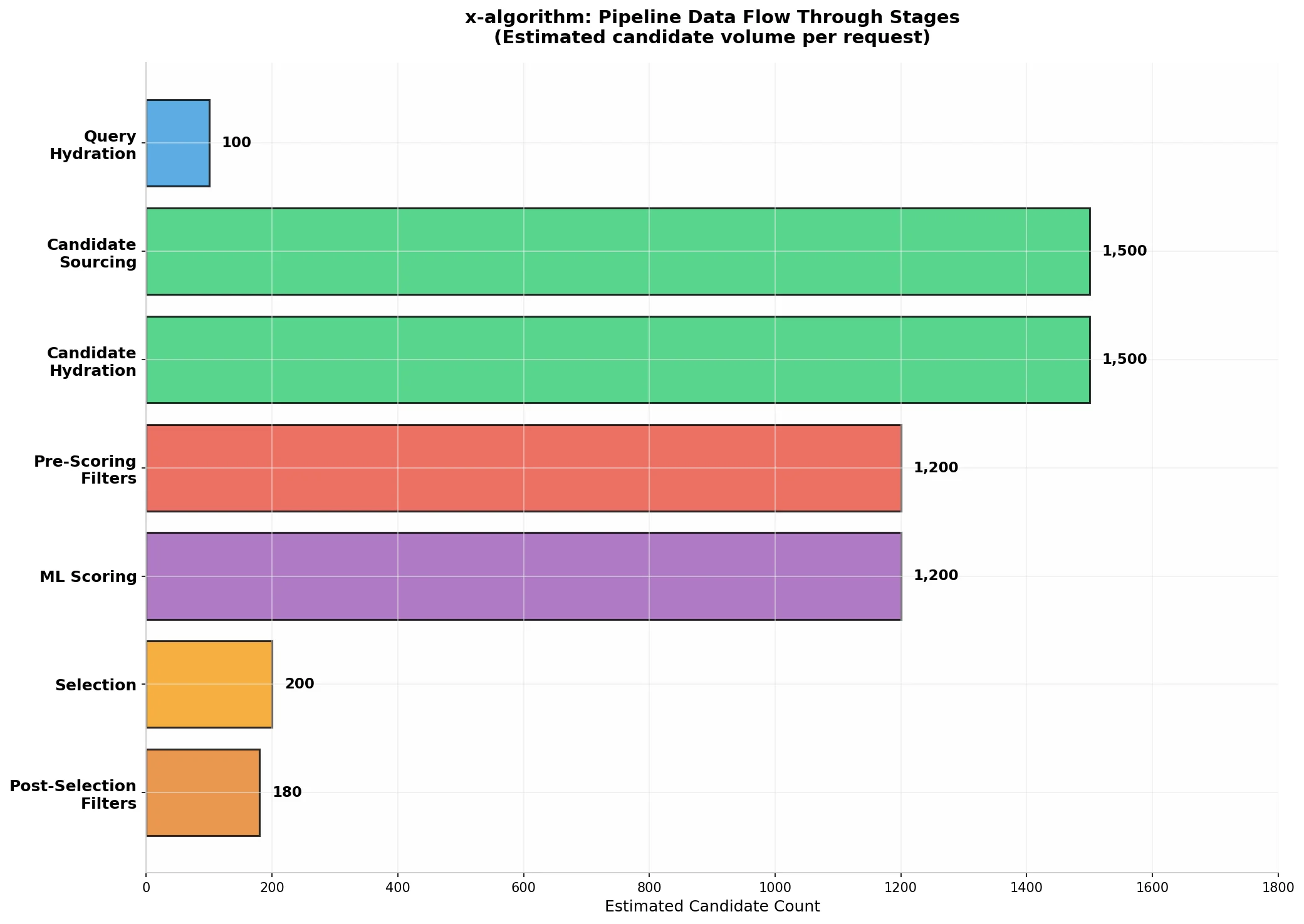
The For You feed generation follows a strict seven-stage pipeline, with each stage filtering or scoring the candidate set, ultimately distilling approximately 1,500 candidate posts down to the most relevant few hundred the user sees.
| Stage | Name | Component | Function | Candidate Volume |
|---|---|---|---|---|
| 1 | Query Hydration | home-mixer/query_hydrators | Fetch user’s recent interaction history, follow list, preferences | N/A |
| 2 | Candidate Sourcing | thunder + phoenix | Thunder provides posts from followed accounts (in-network); Phoenix Two-Tower retrieves similar posts from global corpus (out-of-network) | ~1,500 |
| 3 | Candidate Hydration | home-mixer/candidate_hydrators | Enrich candidates with core metadata (text, media), author info, video duration, subscription status | ~1,500 |
| 4 | Pre-Scoring Filters | home-mixer/filters | Remove duplicates, outdated posts, user’s own posts, blocked accounts, muted keywords | ~1,200 |
| 5 | ML Scoring | phoenix (Grok Transformer) | Phoenix Scorer predicts 15 interaction probabilities; Weighted Scorer combines them; Author Diversity Scorer ensures author diversity | ~1,200 |
| 6 | Selection | home-mixer/selectors | Sort by final score, select Top K (typically ~200) | ~200 |
| 7 | Post-Selection Filters | home-mixer/filters | VFFilter removes deleted/spam/violent content; DedupConversationFilter deduplicates conversation threads | ~180 |
These seven stages are orchestrated by the candidate-pipeline framework, which supports parallel execution of independent stages and provides configurable error handling and logging. Notably, Query Hydration and Candidate Sourcing can execute in parallel to optimize latency, while the Scoring stage, due to its dependency on ML model inference, typically becomes the pipeline’s latency bottleneck.
1.3 Tech Stack: Rust + Python Layered Strategy
x-algorithm employs a layered Rust + Python tech stack, reflecting a deliberate trade-off between performance and flexibility. Rust is used for the infrastructure layer: Home Mixer’s pipeline orchestration, Thunder’s in-memory storage, Candidate Pipeline’s trait framework, and gRPC service interfaces are all implemented in Rust. Rust’s zero-cost abstractions, garbage-collection-free memory management, and excellent concurrency support make it ideal for building high-throughput, low-latency recommendation services. Thunder’s need for sub-millisecond in-network post lookups makes Rust’s performance characteristics critical. Python + JAX is used for the ML layer: Phoenix’s retrieval and ranking models are written in Python, built on the JAX framework and Haiku neural network library. JAX’s functional programming model, automatic differentiation, and XLA compilation support enable seamless transition between research and production environments. The Transformer model in Phoenix is directly inherited from xAI’s open-source Grok-1 implementation, using the same MoE (Mixture of Experts) architecture adapted for recommendation scenarios.
2. Phoenix: The Grok Transformer ML Core
2.1 Two-Tower Retrieval Model: Efficient Candidate Generation
Phoenix’s first stage is Retrieval, which aims to efficiently find the most relevant ~1,500 candidate posts from hundreds of millions of posts. This stage uses the classic Two-Tower Architecture, widely adopted by large-scale recommendation systems like YouTube and Google Play for its excellent scalability.

The User Tower takes user features and interaction history as input, compressing them through a Transformer encoder into a normalized user embedding vector [B, D], where B is batch size and D is embedding dimension. Input features include user ID (looked up via hash table embedding), recent interaction history (post ID, author ID, interaction type, interaction timestamp), and the user’s follow list and preferences. The Candidate Tower encodes all posts into normalized candidate embedding vectors [N, D], where N is the total number of posts in the corpus. Each post’s input features include post ID, author ID, text content features, media features, and product surface features. The two towers use independent parameters for training but compute similarity in the same embedding space. Similarity search uses dot product to compute similarity between the user embedding and all candidate embeddings, selecting the Top-K highest-scoring candidates. Since candidate embeddings can be precomputed and indexed (e.g., using approximate nearest neighbor algorithms like HNSW), online inference only needs to compute the user embedding once, then execute efficient vector retrieval — enabling millisecond-level candidate retrieval from massive corpora.
2.2 Ranking Transformer: The Candidate Isolation Innovation
Phoenix’s second stage is Ranking, which performs fine-grained relevance scoring of the ~1,500 candidates returned by the retrieval stage. This stage uses a Transformer model based on the Grok architecture, with its most critical design innovation being the Candidate Isolation attention mask mechanism.
In the standard Transformer self-attention mechanism, each position in the sequence can attend to all other positions (subject to causal masking). For ranking tasks, this means that if candidate post A can attend to candidate post B, then A’s score depends on whether B is in the same batch — creating serious engineering problems: inconsistent scores across batches, inability to cache candidate scores, and the model learning spurious correlations between co-occurring items rather than genuine user preferences. Phoenix solves this with the make_recsys_attn_mask function:
def make_recsys_attn_mask(seq_len: int, candidate_start_offset: int, dtype: jnp.dtype = jnp.float32): # Base causal mask causal_mask = jnp.tril(jnp.ones((1, 1, seq_len, seq_len), dtype=dtype)) # Block candidate-to-candidate attention (zero out lower right) attn_mask = causal_mask.at[:, :, candidate_start_offset:, candidate_start_offset:].set(0) # Restore candidate self-attention (set diagonal to 1) candidate_indices = jnp.arange(candidate_start_offset, seq_len) attn_mask = attn_mask.at[:, :, candidate_indices, candidate_indices].set(1) return attn_mask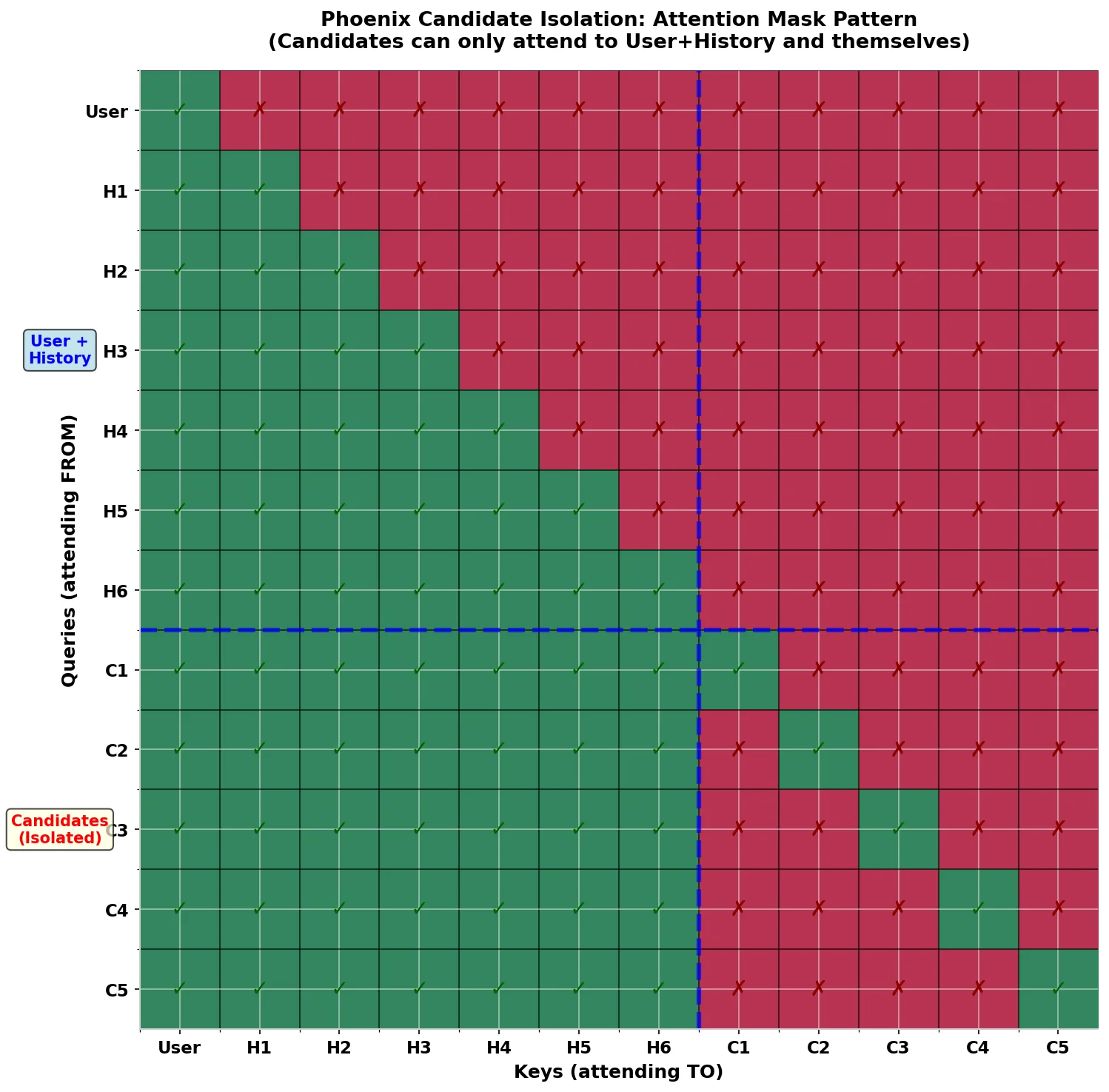
The input sequence is divided into three regions: User prefix (1 position), History (S positions — the user’s recent interaction history), and Candidates (C positions — posts to rank). The masking rules: User and History regions use standard causal attention; all Candidates can attend to User and History (to obtain user context); but Candidates can only self-attend (only the diagonal is 1), they cannot attend to each other. This design delivers four key advantages: Score consistency — the same candidate receives the same score regardless of batch composition; Cacheability — candidate scores can be precomputed and cached offline; Scalability — candidates can be scored independently in parallel without cross-dependencies; Interpretability — scores reflect genuine user-candidate relevance without batch effect interference.
2.3 Multi-Action Prediction: 15-Dimensional Interaction Probability Space
Unlike traditional methods that predict a single “relevance score,” Phoenix’s ranking model simultaneously predicts probabilities for 15 different interaction types, with output dimensions of [B, num_candidates, num_actions]. This multi-task learning approach enables the model to more comprehensively understand users’ multi-dimensional content preferences.
| Action Category | Specific Action | Sentiment | Estimated Weight |
|---|---|---|---|
| Positive | P(favorite) | Positive | ~1.0x |
| Positive | P(reply) | Positive | ~1.0x |
| Positive | P(repost) | Positive | ~1.0x |
| Positive | P(quote) | Positive | ~0.8x |
| Positive | P(click) | Positive | ~0.5x |
| Positive | P(profile_click) | Positive | ~0.6x |
| Positive | P(video_view) | Positive | ~0.7x |
| Positive | P(photo_expand) | Positive | ~0.4x |
| Positive | P(share) | Positive | ~1.0x |
| Positive | P(dwell) | Positive | ~0.8x |
| Positive | P(follow_author) | Positive | ~0.9x |
| Negative | P(not_interested) | Negative | ~-74x |
| Negative | P(block_author) | Negative | ~-74x |
| Negative | P(mute_author) | Negative | ~-74x |
| Negative | P(report) | Negative | ~-74x |
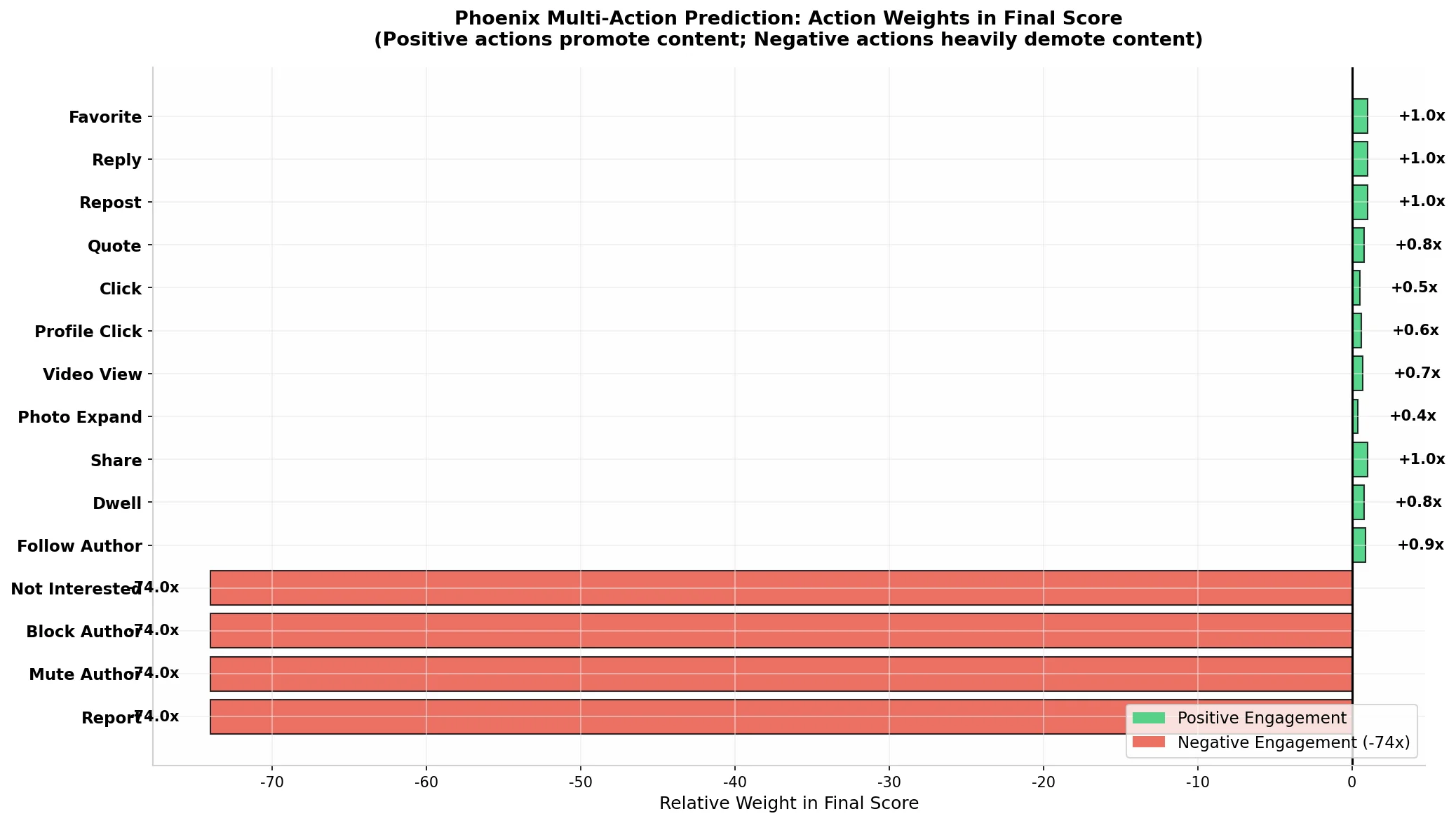
The Weighted Scorer combines these multi-dimensional predictions into a final score: Final Score = Σ(weight_i × P(action_i)). Positive interactions (likes, reposts, shares) have positive weights, pushing content up in ranking; negative interactions (blocks, mutes, reports, not interested) have massive negative weights (~-74x), strongly suppressing content users are unlikely to enjoy. This emphasis on negative signals is a hallmark of the Phoenix architecture — one negative interaction can cancel out dozens of positive ones, enabling the system to precisely avoid showing users content they may find objectionable.
2.4 Hash-Based Embeddings: Compact Representation of Large-Scale Features
Both Phoenix’s retrieval and ranking models use multi-hash function embedding lookups to handle high-cardinality categorical features (such as user IDs, post IDs, author IDs). Unlike traditional large embedding tables (vocabulary size × embedding_dim), hash embeddings use multiple independent hash functions to map high-cardinality IDs into a low-dimensional embedding space, combining embeddings from multiple hash buckets during lookup. The advantages include: Memory efficiency — no need to store a complete vocabulary embedding table, significantly reducing model memory footprint; Cold start handling — hash functions still produce reasonable embeddings for IDs not seen during training; Training stability — combining multiple hash functions reduces the impact of individual hash collisions. In Phoenix’s open-source examples, embedding tables containing 1 million hash buckets are provided (1.4 GB each for retrieval and ranker), along with precomputed candidate representations for 537,000 posts from a sports corpus.
3. Infrastructure Components: High-Performance, Low-Latency Service Architecture
3.1 Home Mixer: The Central Nervous System of Pipeline Orchestration
Home Mixer is the Orchestration Layer of the entire recommendation system, responsible for coordinating Phoenix’s ML capabilities with the system’s other components to assemble the final For You feed. It is built on the candidate-pipeline framework, abstracting the recommendation process into multiple composable stages, each handled by components implementing specific traits. Home Mixer’s core is a gRPC service (ScoredPostsService) that receives user requests and executes pipeline stages in a predefined order. This component is written in Rust, leveraging its async runtime (likely Tokio) for high-concurrency request processing. From the code structure, Home Mixer includes the following key modules: sources/ (defines candidate sources like Thunder and Phoenix Retrieval), candidate_hydrators/ (candidate feature enrichment), filters/ (candidate filtering logic), scorers/ (scoring logic, including Phoenix ML Scorer), selectors/ (sorting and selection), query_hydrators/ (query context enrichment), and side_effects/ (async side effects like caching and logging).
This modular trait-based design gives the system exceptional extensibility — engineers can easily add new candidate sources, new scorers, or new filters without modifying existing pipeline logic. For example, adding a new “trending topics” candidate source only requires implementing the Source trait and registering it in the pipeline. Similarly, experimenting with a new scoring strategy only requires implementing the Scorer trait and enabling it in configuration. This “composable pipeline architecture” is one of x-algorithm’s core engineering philosophies.
3.2 Thunder: Sub-Millisecond In-Network Content Storage
Thunder is X’s in-network content service layer, specifically responsible for storing and serving recent posts from accounts the user follows. Unlike out-of-network content that requires querying large databases, Thunder maintains all followed accounts’ posts in memory, achieving sub-millisecond lookup latency. Thunder’s core architecture includes: Kafka consumption pipeline — Thunder consumes post creation/deletion event streams from Kafka, updating in-memory data storage in real-time; Layered storage structure — maintains independent storage areas per user, separately storing original posts, reply/retweet posts, and video posts for type-based fast retrieval; Automatic expiry pruning — posts exceeding retention period are automatically removed from memory to control memory usage. Thunder is written in Rust, the ideal choice for achieving extremely low-latency memory operations. From the code structure, Thunder includes a kafka/ directory (Kafka consumer implementation), a posts/ directory (post data structures and storage logic), thunder_service.rs (gRPC service interface), and deserializer.rs (post deserialization logic). Thunder’s high performance is critical for the X platform — in-network content typically constitutes a significant portion of a user’s feed, and users expect to see the latest posts from followed accounts with extremely low latency.
3.3 Candidate Pipeline: Composable Recommendation Framework
The candidate-pipeline is x-algorithm’s general-purpose recommendation pipeline framework, defining a set of trait interfaces for building modular recommendation systems. The framework’s core design goal is to separate pipeline execution and monitoring logic from business logic, allowing engineers to focus on implementing specific recommendation strategies without worrying about underlying concurrent execution, error handling, and metrics collection.
| Trait | Core Method | Description | Concurrency |
|---|---|---|---|
Source<Q, C> |
source(&self, query: &Q) -> Result<Vec<C>, String> |
Fetch candidate list from data source | Parallel |
Hydrator<Q, C> |
hydrate(&self, query: &Q, candidate: &mut C) |
Enrich candidates with additional features | Parallel |
Filter<Q, C> |
filter(&self, query: &Q, candidate: &C) -> bool |
Determine whether to remove a candidate | Serial |
Scorer<Q, C> |
score(&self, query: &Q, candidate: &mut C) |
Compute candidate score | Serial |
Selector<Q, C> |
select(&self, candidates: &mut [C]) -> SelectResult<C> |
Sort and select Top K | Serial |
SideEffect<Q, C> |
run(&self, input: SideEffectInput<Q, C>) |
Execute async side effects | Async |
The Source trait implementation example demonstrates the framework’s design philosophy: each Source must implement the source() method returning a candidate list, while the run() wrapper method is provided by the framework, automatically adding logging, performance statistics (via the xai_stats_macro::receive_stats attribute macro), and distributed tracing (via the tracing::instrument attribute macro). This design gives every component automatic observability support without developers hardcoding monitoring code in business logic. The framework also executes sources and hydrators in parallel to optimize latency — multiple candidate sources can be fetched concurrently, and multiple hydrators can also concurrently enrich candidates.
4. Key Design Decisions: Deep Engineering-Algorithm Trade-offs
4.1 Eliminating Manual Feature Engineering: The Pure ML Paradigm Shift
One of x-algorithm’s most striking design decisions is the complete elimination of hand-engineered features. In traditional recommendation systems, engineers must manually design and maintain numerous features — user interaction counts, post popularity scores, time decay factors, author authority metrics, etc. While intuitively interpretable, these manual features carry significant maintenance burdens and scalability limitations. The Phoenix architecture transfers this responsibility entirely to the Grok-based Transformer model. The model learns relevance judgments directly from raw user interaction sequences, automatically discovering which signal combinations best predict future user behavior. The philosophical foundation of this “feature-free” approach is: the Transformer’s attention mechanism inherently possesses powerful feature extraction capabilities, automatically learning hierarchical representations from raw input. For recommendation systems, a user’s interaction history (liked post A, replied to post B, retweeted post C) is itself the richest feature signal, and the Transformer can capture complex patterns between these interactions through self-attention (e.g., “users who like tech posts typically reply to related discussion threads afterward”). This design significantly reduces data pipeline complexity — no more maintaining complex feature generation and backfill pipelines, no more dealing with feature version compatibility issues. However, this approach also brings new challenges: reduced model interpretability, increased dependence on training data quality and scale, and greater debugging difficulty.
4.2 Candidate Isolation’s Engineering Value: From Consistency to Scalability
Candidate Isolation is not just an algorithmic innovation in Phoenix; it’s a design decision with profound engineering implications. In industrial-grade recommendation systems, the ranking stage typically processes hundreds to thousands of candidates, each requiring inference scoring through complex neural networks. Without Candidate Isolation, every batch composition change causes score changes, making the following optimizations impossible: Score caching — cannot cache precomputed scores for popular candidates, requiring re-inference per request; Incremental updates — when new candidates join, all scores in the batch must be recomputed; A/B test reliability — score batch-dependency makes experimental results difficult to interpret; Offline precomputation — cannot precompute candidate scores on large batches for online fast lookup. Candidate Isolation fundamentally solves these problems by ensuring each candidate’s score depends only on the user context (User + History) and not on other candidates. In practice, this means Phoenix can: actively cache popular candidates’ scores, significantly reducing ML inference load; support incremental candidate addition and removal without recomputing the entire batch; conduct more reliable model A/B tests since scores are unaffected by batch composition. These engineering advantages enable Phoenix to maintain low latency and high throughput at X platform’s massive traffic scale (processing over 100 million posts daily).
4.3 Composable Architecture: Balancing Modularity and Extensibility
The candidate-pipeline framework’s composable architecture represents best-practice modern recommendation system engineering. By decomposing the recommendation flow into six core abstractions — Source, Hydrator, Filter, Scorer, Selector, and SideEffect — the system achieves complete separation of business logic from execution framework. This architecture’s advantages manifest at multiple levels: Experimental agility — new recommendation strategies can be quickly implemented by combining existing components without modifying core pipeline code; Progressive deployment — new components can be A/B tested on small traffic before full rollout; Fault isolation — individual component failures don’t crash the entire pipeline, with the framework providing graceful error handling; Cross-team parallel development — different teams can independently develop and maintain their respective components (e.g., ML team owns Scorer, content safety team owns Filter), integrated through standard interfaces. From the candidate_pipeline.rs implementation, the framework uses Rust’s trait system and async runtime to achieve these goals. The pipeline executor schedules and coordinates execution order across stages, handles inter-stage dependencies, and collects performance metrics per stage. This separation of concerns effectively manages system complexity — each component focuses solely on its business logic while execution, monitoring, and error handling are uniformly managed by the framework.
4.4 Multi-Action vs Single-Score Prediction: Fine-Grained User Modeling
Phoenix’s multi-action prediction design (simultaneously predicting probabilities for 15 interaction types) represents a refinement in recommendation system modeling methodology. Traditional systems typically predict a single “relevance score” or “click probability” — while this simplification reduces model complexity, it loses multi-dimensional user behavior information. The core advantages of multi-action prediction include: Fine-grained user preference modeling — different users have different interaction patterns for different content types. Some users tend to “lurk” (high dwell time but low interaction), while others actively engage in discussion (high reply rate). By separately predicting the probabilities for each action type, the model can better match content to users’ interaction styles. Multi-dimensional content quality assessment — a high-quality news article might receive many dwells and shares but few replies, while a controversial topic might generate many replies and quotes but also more reports. Multi-dimensional prediction enables the system to distinguish these different content quality patterns. Explicit negative signal modeling — by explicitly predicting the probabilities of not_interested, block, mute, and report, the system can actively avoid recommending content that users may find objectionable, rather than only passively optimizing for positive interactions. When the Weighted Scorer combines these multi-dimensional predictions into a final score, it employs an asymmetric weighting strategy — negative signals’ weight (~-74x) is far larger than positive signals’ weight (~1x). This design reflects a core principle of recommendation systems: the cost of showing a bad recommendation far exceeds the benefit of showing a good one. A recommended content that annoys a user can lead to churn, while missing an interesting post is only a minor experience loss.
5. Industry Comparison and Historical Context
5.1 2023 vs 2026: From “Transparency Theater” to Production-Grade Open Source
X (Twitter) has undergone two distinctly different attempts at recommendation algorithm open-sourcing, and their comparison reveals the industry’s evolution in algorithmic transparency. The March 2023 initial open-source release on GitHub’s twitter/the-algorithm repository, while generating massive buzz, was quickly criticized as “transparency theater.” Key issues included: incomplete code — only “partial” code was released, missing critical components; inconsistency with production — the open-source code deviated from what actually ran in production; lack of documentation — code had almost no comments or architectural explanations; stalled updates — updates stopped shortly after release, with code gradually diverging from the actual system. Elon Musk acknowledged at the time: “Providing code transparency will be embarrassing at first, but will ultimately lead to rapid recommendation quality improvement.” The January 2026 Phoenix open-source release represents a fundamental change: complete production system — what was open-sourced is the actual system running in production, deployed on release day; comprehensive documentation — detailed README, architecture diagrams, and component descriptions; regular update commitment — pledging updates every four weeks with developer notes; Apache 2.0 license — allowing commercial use and modification. This “ship what we deploy” strategy eliminates the credibility gap of the 2023 release, enabling developers and researchers to verify the code that’s actually running.
| Comparison Dimension | 2023 Initial Open Source | 2026 Phoenix Open Source |
|---|---|---|
| Code Completeness | Partial components | Full production system |
| Production Consistency | Divergent | Ship what we deploy |
| Architecture Foundation | Hand-crafted rules + heuristics | Grok Transformer ML |
| Documentation Quality | Almost none | Detailed diagrams and explanations |
| Update Cadence | Abandoned | Every 4 weeks |
| License | Unclear | Apache 2.0 |
| Community Stars | ~60k (initial) | ~20.8k (growing) |
| Industry Verdict | “Transparency theater” | “Industry benchmark” |
5.2 Transparency Comparison with Other Social Platforms
In algorithmic transparency, X’s Phoenix open-source leads among mainstream social platforms. Meta (Facebook/Instagram) — has never open-sourced its recommendation algorithm, only disclosing partial technical details through blog posts and academic papers; its algorithms are considered among the most complex in the industry but completely closed. TikTok — the “For You” feed algorithm is considered its core trade secret, with code never made public; only general creator guidelines explaining recommendation principles are provided. YouTube — Google has disclosed partial technology through academic papers (e.g., Deep Neural Networks for YouTube Recommendations) but never open-sourced production code. Snapchat — completely closed algorithms with almost no technical disclosure. X’s Phoenix open-source thus becomes the first production-grade recommendation system completely open-sourced by a mainstream social platform. This transparency level also carries regulatory significance — the EU’s Digital Services Act (DSA) requires algorithmic transparency from large platforms, and X’s open-source release can be seen as a proactive response to this regulatory pressure. Open-sourcing also enables researchers to independently audit the algorithm, verifying claims about bias, suppression, or amplification of specific content — rather than relying solely on the platform’s self-reporting.
5.3 Cross-Domain Grok Tech Stack: From LLM to Recommendation System
A unique aspect of the Phoenix architecture is its direct use of xAI’s Grok large language model technology stack. Grok-1 is a 314 billion parameter Mixture of Experts (MoE) model open-sourced by xAI in March 2024, using 8 expert networks with 2 experts activated per token. Its core technical specifications include: 64 Transformer layers, 48 query attention heads, 8 key/value attention heads, 6,144-dimensional embeddings, SentencePiece tokenizer (131,072 tokens), RoPE (Rotary Position Embedding), and a maximum context length of 8,192 tokens. Phoenix’s Transformer implementation is directly ported from Grok-1’s open-source code, retaining core architectural features (such as grouped-query attention, RMSNorm layer normalization, RoPE position encoding) with the following key adaptations: Input embedding layer modification — from text token embeddings to recommendation-specific hash embeddings handling categorical features like user IDs, post IDs, author IDs; Custom attention mask — implementing the Candidate Isolation mask make_recsys_attn_mask, replacing standard causal masking; Output head expansion — from a single language modeling head to 15 independent action prediction heads, each predicting the probability of one interaction type; Sequence structure redefinition — input sequence restructured from pure text token sequences to a structured [User, History_1, ..., History_N, Candidate_1, ..., Candidate_M] format. This cross-domain application from LLM to recommendation system exemplifies the Foundation Model philosophy — Grok’s Transformer architecture, as a general-purpose sequence modeling capability, can be applied to different domain tasks through moderate adaptation. It also demonstrates xAI’s deep integration of the Grok technology stack into X platform infrastructure — the two companies share not just ownership but also foundational technology.
6. Practical Implications for Developers and Content Creators
6.1 Technical Reference Value for Developers
x-algorithm’s open-source provides rich learning resources and technical references for recommendation system developers and researchers. Architecture pattern reference: the Two-Tower retrieval + Transformer ranking two-stage architecture represents current best practice for large-scale recommendation systems, with x-algorithm providing a complete production-grade implementation. The Candidate Isolation attention mask design particularly offers innovative ideas for solving ranking stage scalability issues. Composable pipeline framework: candidate-pipeline’s trait-based design demonstrates how to use Rust’s type system to build modular, extensible recommendation pipelines. This pattern can be adapted to other languages and scenarios. ML engineering practices: Phoenix’s code shows how to deploy large Transformer models to high-throughput, low-latency production environments, including practices for model export (model_params.npz), embedding table management (embedding_tables.npz), and configuration management (config.json). End-to-end ML paradigm: the shift from manual feature engineering to pure ML-driven approach provides valuable migration experience, including handling training data construction, model debugging, and online/offline consistency challenges.
6.2 Algorithm Insights for Content Creators
For X platform content creators, the open-source code provides unprecedented algorithmic insights to optimize content strategy for greater organic reach. Interaction quality matters far more than quantity: the algorithm predicts 15 different interaction types with different weights. High-engagement actions like reply, repost, and share carry higher weight than passive likes. Creators should design content that sparks discussion and sharing, not just likes. Negative signals have devastating impact: Not Interested, Block, Mute, and Report carry approximately -74x weight, meaning one negative interaction can cancel out dozens of positive ones. Creators should avoid posting content that may generate controversy or dislike. Dwell time is a hidden key signal: the algorithm explicitly predicts dwell action probability — the longer users spend on a post, the more likely the algorithm will recommend it. This emphasizes the importance of creating content that makes users “stop and read” — compelling openings, well-structured paragraphs, and narrative arcs. External links face significant suppression: posts containing external links typically suffer 30-50% or higher reach penalties. Strategically, creators should place external links in replies rather than the main post, or post core content directly on X. Author diversity constraints: the Author Diversity Scorer reduces scores for multiple posts from the same author to ensure feed diversity, meaning even popular creators face quantity limits on their content in a single user’s feed.
7. Limitations and Open Questions
7.1 Components Not Open-Sourced
While x-algorithm open-sources the core recommendation logic, the following key components remain closed: Specific weight constants — while the Weighted Scorer’s architecture is open-source, the exact weight values for each action type are redacted in production code, preventing developers from knowing the precise weight ratios between P(favorite) and P(reply). Training data and training code — model architecture and inference code are open-sourced, but training datasets, training procedures, and loss function implementations are not included. User profile data — user features obtained during the Query Hydration stage (such as specific user preference representations) are not fully disclosed. Ad recommendation logic — while Musk promised to open-source “all code used to determine which organic and ad posts to recommend to users,” the specific business logic for ad ranking may still be reserved. Content moderation models — VFFilter is used to remove deleted/spam/violent/graphic content, but its underlying content moderation model is not open-sourced. Real-time infrastructure — Thunder’s in-memory storage logic is open-sourced, but the underlying Kafka cluster configuration, data replication strategy, and failure recovery mechanisms are not public.
7.2 Technical Challenges and Future Directions
x-algorithm’s current architecture still faces several technical challenges: Cold start problem — while hash embeddings provide some capability for unseen IDs, recommendation quality for new users and new posts may still not match that for established users and popular posts. Sequence length limitations — the Transformer’s limited context window cannot capture a user’s complete interaction history, relying only on recent interaction sequences. Computational cost — while the MoE architecture reduces inference costs through sparse activation, the Phoenix ranking model still requires Transformer forward passes on hundreds of candidates, representing a significant computational burden at high traffic volumes. Diversity-relevance balance — the Author Diversity Scorer increases diversity by reducing scores for repeated authors, but this may conflict with genuine user preferences (users may genuinely want to see all content from a favorite author). Future development directions may include: Longer context windows — leveraging Grok-3’s 1 million token context capability to capture longer user histories. Multi-modal understanding — Grok-1.5V already supports image and video understanding, and future Phoenix versions may directly process visual content from posts rather than relying solely on text and metadata features. Reinforcement learning optimization — shifting from supervised learning (predicting user behavior) to reinforcement learning (optimizing long-term user satisfaction), which may further improve recommendation quality.
7.3 Engineering Implementation Details from the Code
Deep analysis of x-algorithm’s source code reveals several noteworthy engineering details. In grok.py, the right_anchored_rope_positions function implements a special position encoding strategy — right-anchored RoPE (Rotary Position Embedding). This strategy ensures that the most recent historical token always receives a fixed position number regardless of the actual length of the history sequence. In the implementation, the history_end position is fixed at the maximum history length, while actual historical token positions are dynamically computed based on current history length: position = history_end - history_len + idx - history_start. The intuition behind this design: the user’s most recent interaction behavior is most important for predicting current interests; by anchoring the latest interaction to a fixed position, the model can more stably learn the “recency” signal. For the candidate region (idx >= history_end), all candidates share the same position encoding history_end, further reinforcing the Candidate Isolation design philosophy — candidates should not be distinguished from each other through position encoding.
The compute_post_age_bucket function in recsys_model.py demonstrates how to handle discretization of continuous numerical features. Post age (the time interval from publication to display) is divided into hour-granularity buckets, supporting up to 4,800 minutes (approximately 3.3 days), with posts exceeding this range placed in an overflow bucket. The advantages of this discretization strategy include: reducing model sensitivity to exact numerical values, making the model focus on “was the post published 2 hours ago or 5 hours ago” rather than “was the post published 7,234 seconds ago”; handling edge cases through a special bucket 0 for posts with missing or abnormal timestamps. This function is implemented using JAX’s vectorized operations, supporting efficient batch computation on GPU/TPU, reflecting Phoenix’s attention to performance optimization.
In candidate_pipeline.rs, pipeline execution is explicitly modeled through the PipelineStage enum and PipelineComponents struct. The PipelineResult struct records candidate volume changes at each stage (retrieved_candidates, filtered_candidates, selected_candidates). This detailed metrics collection enables engineers to precisely track each component’s impact on the candidate set, quickly identifying pipeline bottlenecks or anomalies. The framework uses futures::future::join_all to implement parallel execution of Source and Hydrator stages, and automatically adds performance statistics and distributed tracing support to each component method through the xai_stats_macro::receive_stats procedural macro — engineering details that reflect xAI team’s systematic thinking in building observability.
8. Conclusion: A New Benchmark for Algorithm Transparency
xAI’s open-source x-algorithm represents a new benchmark for social media algorithm transparency. By placing a complete production-grade recommendation system (not partial code or academic prototypes) under the Apache 2.0 license, X platform has set an unprecedented transparency standard for the industry. The profound significance of this release manifests at multiple levels: Technologically, the Phoenix architecture demonstrates how to successfully apply large Transformer models (originating from the Grok LLM technology stack) to large-scale recommendation systems, with the Candidate Isolation attention mask providing innovative solutions for ranking stage scalability. Engineering-wise, the candidate-pipeline composable pipeline framework and Rust + Python layered tech stack strategy offer replicable engineering practices for building high-throughput, low-latency recommendation services. Industry-wise, against the backdrop of Meta, TikTok, YouTube, and other platforms keeping their algorithms completely closed, X’s open-source release establishes a new benchmark for algorithmic transparency and auditability, potentially pushing the entire industry toward greater openness. Societally, open-sourcing enables independent researchers to verify claims about algorithmic bias, content amplification, and information suppression, providing a foundation of code-based evidence for public discourse rather than speculation. Of course, x-algorithm’s open-source is not perfect — specific weight constants, training data, and some infrastructure remain closed, and the system’s actual operation depends on numerous unopened peripheral components. Nevertheless, this release remains one of the most influential open-source events in the recommendation system field, its value lying not just in the concrete code implementation but in the “ship what we deploy” transparency commitment it represents — regular four-week updates will keep this transparency sustained and verifiable. For recommendation system practitioners, researchers, and content creators, x-algorithm provides invaluable learning resources and practical insights, with its design philosophy and engineering decisions likely to influence the direction of recommendation system development for years to come.
References
- [^1^] xAI. (2026). x-algorithm: Algorithm powering the For You feed on X. GitHub Repository. https://github.com/xai-org/x-algorithm
- [^2^] xAI. (2026). Phoenix: Recommendation System. https://github.com/xai-org/x-algorithm/tree/main/phoenix
- [^8^] xAI. (2026). grok.py: Transformer implementation. https://github.com/xai-org/x-algorithm/blob/main/phoenix/grok.py
- [^9^] xAI. (2026). candidate_pipeline.rs. https://github.com/xai-org/x-algorithm/blob/main/candidate-pipeline/candidate_pipeline.rs
- [^10^] xAI. (2026). source.rs. https://github.com/xai-org/x-algorithm/blob/main/candidate-pipeline/source.rs
- [^11^] BASENOR. (2026). X Recommendation Algorithm Gets Major Update. https://www.basenor.com/blogs/news/x-recommendation-algorithm-gets-major-update-and-goes-open-source
- [^12^] TechCrunch. (2026). X open sources its algorithm. https://techcrunch.com/2026/01/20/x-open-sources-its-algorithm-while-facing-a-transparency-fine-and-grok-controversies/
- [^13^] Conbersa AI. (2026). How Does the X Algorithm Work in 2026? https://www.conbersa.ai/learn/what-is-twitter-algorithm
- [^16^] Mintlify. (2026). Candidate Isolation. https://mintlify.com/xai-org/x-algorithm/concepts/candidate-isolation
- [^17^] OpenTweet. (2026). 10 X Algorithm Secrets. https://opentweet.io/blog/x-algorithm-secrets-2026
- [^19^] Typefully. (2026). X Algorithm Update. https://typefully.com/blog/x-algorithm-open-source
- [^20^] Shaped. (2025). Two-Tower Model Deep Dive. https://www.shaped.ai/blog/the-two-tower-model-for-recommendation-systems-a-deep-dive
- [^22^] xAI. (2024). Grok-1. https://github.com/xai-org/grok-1
- [^24^] Systems Analysis Wiki. (2026). Grok Architecture. https://systems-analysis.ru/int/index.php?title=Grok_(xAI)
- [^29^] BASENOR. (2026). X Algorithm Technical Analysis. https://www.basenor.com/blogs/news/x-recommendation-algorithm-gets-major-update-and-goes-open-source
- [^31^] PPC.land. (2026). X exposes algorithm secrets. https://ppc.land/x-exposes-algorithm-secrets/