深度解析 xAI 开源的 X 推荐算法:从 Phoenix 架构到 For You Feed 的完整技术剖析
深度解析 xAI 开源的 X 推荐算法:从 Phoenix 架构到 For You Feed 的完整技术剖析
快速概览
2026 年 1 月,xAI 在 GitHub 上开源了驱动 X(原 Twitter)平台 “For You” 信息流的核心推荐算法代码仓库 xai-org/x-algorithm,截至目前已获得超过 20,800 个星标 和 3,600 次分支。与 2023 年 Twitter 首次部分开源的 “透明度戏剧” 不同,这次发布代表了架构层面的彻底重写——从依赖人工设计规则的传统系统转变为基于 Grok transformer 模型 的端到端机器学习驱动架构。该系统采用 双塔模型(Two-Tower Model) 进行候选内容的高效检索,通过 候选隔离(Candidate Isolation)注意力掩码 实现的 Transformer 排序模型进行精排,并利用 可组合流水线框架(Candidate Pipeline) 将查询 hydration、候选 sourcing、过滤、评分和选择等环节有机串联。本文将从系统架构、核心组件、ML 模型设计、关键工程决策以及行业对比等维度,对这一具有行业标杆意义的开源推荐系统进行全面深入的技术剖析。
1. 系统架构全景:五层协作的推荐流水线
1.1 架构设计理念:从规则驱动到端到端学习
X 的推荐算法在 2026 年经历了根本性的架构范式转变。2023 年 3 月 Twitter 首次开源的推荐代码被批评者形容为 “纠缠的意大利面条代码和手动过滤器”,其系统依赖复杂的集群和启发式规则,内容在发布数小时后仍通过这些人工设计的规则逐步获得分发。而 2026 年 1 月发布的全新系统——内部代号为 “Phoenix”——则彻底消除了所有手工设计的特征和大多数启发式规则。这一转变的核心驱动力来自 xAI 的 Grok 大语言模型技术栈,Phoenix 架构直接采用与 Grok 相同的 Transformer 架构,将其适配到推荐系统场景中。这种端到端的学习方法意味着模型直接从用户的 engagement 序列(点赞、回复、转发、停留时间等)中学习相关性判断,而非依赖工程师预先定义的规则。这一设计选择显著降低了数据管道和服务基础设施的复杂性,同时也使系统能够更快地适应用户行为的变化。根据 xAI 的官方说明,Grok-based Transformer 承担了系统中的 “所有重活”,通过理解用户的 engagement 历史来确定什么内容对用户是相关的。
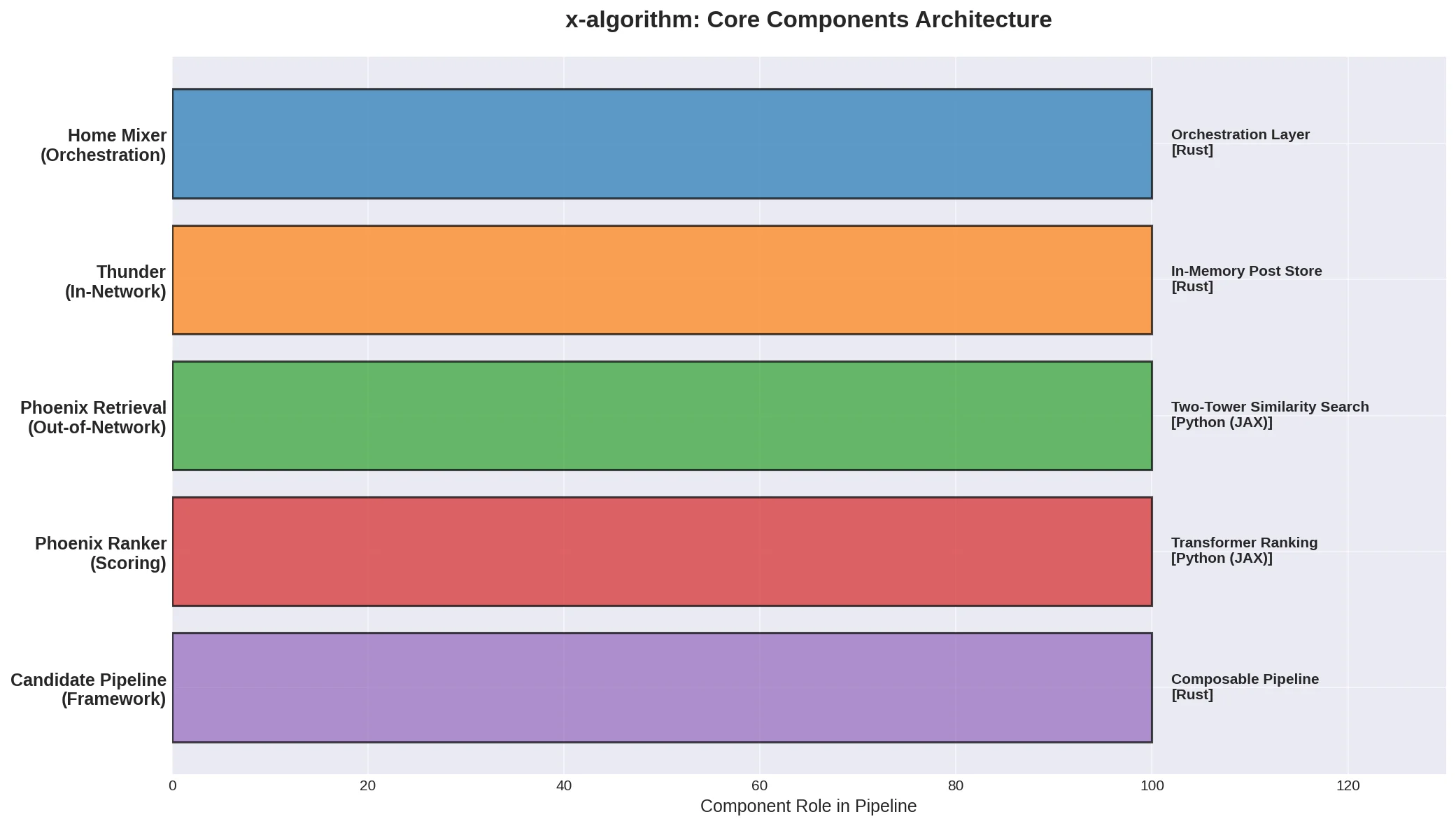
上图展示了 x-algorithm 的五大核心组件及其在推荐流水线中的角色。整个系统采用 Rust(57.4%) 和 Python(42.6%) 混合编写,其中基础设施层使用 Rust 保证高性能和低延迟,ML 模型层使用 Python + JAX 进行灵活的深度学习计算。
1.2 流水线执行流程:从请求到响应的七阶段处理
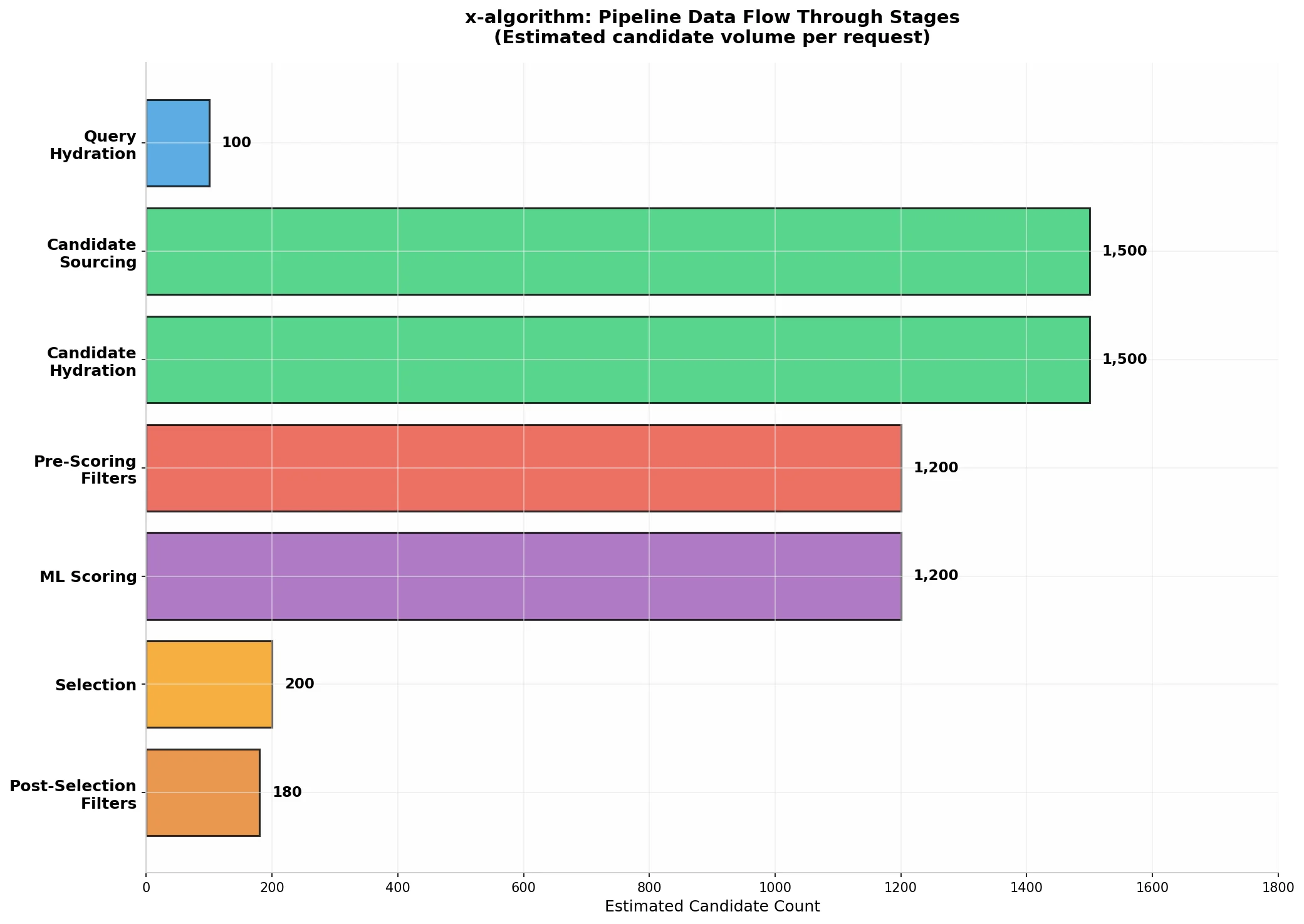
For You feed 的生成遵循严格的七阶段流水线处理流程,每个阶段都对候选集进行筛选或排序,最终将约 1,500 个候选帖子 精简为用户看到的最相关的数百条内容。
| 阶段编号 | 阶段名称 | 处理组件 | 核心功能 | 候选集规模变化 |
|---|---|---|---|---|
| 1 | Query Hydration | home-mixer/query_hydrators | 获取用户近期互动历史、关注列表、偏好设置等上下文 | N/A |
| 2 | Candidate Sourcing | thunder + phoenix | Thunder 提供已关注账户的帖子(in-network);Phoenix 双塔模型从全局语料库检索相似帖子(out-of-network) | ~1,500 |
| 3 | Candidate Hydration | home-mixer/candidate_hydrators | 补充候选帖子的核心元数据(文本、媒体)、作者信息、视频时长、订阅状态等 | ~1,500 |
| 4 | Pre-Scoring Filters | home-mixer/filters | 移除重复、过旧、用户自己发布的、来自被屏蔽账户的、含被静音关键词的帖子 | ~1,200 |
| 5 | ML Scoring | phoenix (Grok Transformer) | Phoenix Scorer 预测 15 种互动概率;Weighted Scorer 加权组合;Author Diversity Scorer 确保作者多样性 | ~1,200 |
| 6 | Selection | home-mixer/selectors | 按最终分数排序并选取 Top K(通常约 200 个) | ~200 |
| 7 | Post-Selection Filters | home-mixer/filters | VFFilter 移除已删除/垃圾/暴力内容;DedupConversationFilter 对同一会话分支去重 | ~180 |
这七个阶段通过 candidate-pipeline 框架进行编排,该框架支持并行执行独立的阶段,并提供可配置的错误处理和日志记录。值得注意的是,Query Hydration 和 Candidate Sourcing 阶段可以并行执行以优化延迟,而 Scoring 阶段由于其对 ML 模型推理的依赖,通常成为整个流水线的延迟瓶颈。
1.3 技术栈选择:Rust + Python 的分层策略
x-algorithm 采用 Rust 和 Python 的分层技术栈策略,这一选择体现了系统在性能与灵活性之间的深思熟虑的权衡。Rust 被用于基础设施层:Home Mixer 的流水线编排、Thunder 的内存存储、Candidate Pipeline 的 trait 框架以及 gRPC 服务接口全部使用 Rust 实现。Rust 的零成本抽象、无垃圾回收的内存管理以及出色的并发支持使其成为构建高吞吐、低延迟推荐服务的理想选择。特别是 Thunder 组件需要实现亚毫秒级的 in-network 帖子查找,Rust 的性能特性对此至关重要。Python + JAX 被用于 ML 层:Phoenix 的检索和排序模型使用 Python 编写,基于 JAX 框架和 Haiku 神经网络库实现。JAX 的函数式编程模型、自动微分以及 XLA 编译支持使其特别适合研究和生产环境之间的无缝过渡。Phoenix 中的 Transformer 模型直接继承自 xAI 开源的 Grok-1 实现,使用相同的 MoE(Mixture of Experts)架构基础,但针对推荐场景进行了适配。
2. Phoenix:基于 Grok Transformer 的 ML 核心
2.1 双塔检索模型:高效候选生成
Phoenix 的第一阶段是 检索(Retrieval),其目标是从数以亿计的帖子中高效地找出最相关的约 1,500 个候选帖子。这一阶段采用经典的双塔架构(Two-Tower Architecture),该架构因其出色的可扩展性而被 YouTube、Google Play 等大型推荐系统广泛采用。

用户塔(User Tower) 接收用户的特征和互动历史作为输入,通过 Transformer 编码器将其压缩为一个归一化的用户嵌入向量 [B, D],其中 B 是批次大小,D 是嵌入维度。输入特征包括用户 ID(通过 hash 查表获取嵌入)、近期互动历史(帖子 ID、作者 ID、互动类型、互动时间戳等)以及用户的关注列表和偏好设置。候选塔(Candidate Tower) 将所有帖子编码为归一化的候选嵌入向量 [N, D],其中 N 是语料库中的帖子总数。每个帖子的输入特征包括帖子 ID、作者 ID、文本内容特征、媒体特征以及产品表面特征(如来自哪个平台界面)。两个塔使用独立的参数进行训练,但最终在同一个嵌入空间中进行相似度计算。相似度搜索通过向量点积(dot product)计算用户嵌入与所有候选嵌入的相似度,选取 Top-K 最高的候选。由于候选嵌入可以预先计算并索引(例如使用 HNSW 等近似最近邻算法),在线推理时只需要计算用户嵌入一次,然后执行高效的向量检索,这使得系统能够在毫秒级时间内从海量语料库中检索候选。
2.2 排序 Transformer:候选隔离的关键创新
Phoenix 的第二阶段是 排序(Ranking),其目标是对检索阶段返回的约 1,500 个候选帖子进行精细化的相关性排序。这一阶段采用了基于 Grok 架构的 Transformer 模型,其最关键的设计创新是 候选隔离(Candidate Isolation) 注意力掩码机制。
在标准 Transformer 的自注意力机制中,序列中的每个位置都可以 attend 到其他所有位置(受因果掩码限制)。对于推荐系统排序任务,这意味着如果候选帖子 A 可以 attend 到候选帖子 B,那么 A 的分数将依赖于 B 是否在同一批次中——这带来了严重的工程问题:分数在不同批次间不一致、无法缓存候选分数、以及模型可能学到共现项目之间的虚假关联而非真实的用户偏好。Phoenix 通过 make_recsys_attn_mask 函数实现了一个特殊的注意力掩码来解决这一问题:
def make_recsys_attn_mask(seq_len: int, candidate_start_offset: int, dtype: jnp.dtype = jnp.float32): # 基础因果掩码 causal_mask = jnp.tril(jnp.ones((1, 1, seq_len, seq_len), dtype=dtype)) # 屏蔽候选-候选之间的注意力(右下角置零) attn_mask = causal_mask.at[:, :, candidate_start_offset:, candidate_start_offset:].set(0) # 恢复候选的自注意力(对角线置一) candidate_indices = jnp.arange(candidate_start_offset, seq_len) attn_mask = attn_mask.at[:, :, candidate_indices, candidate_indices].set(1) return attn_mask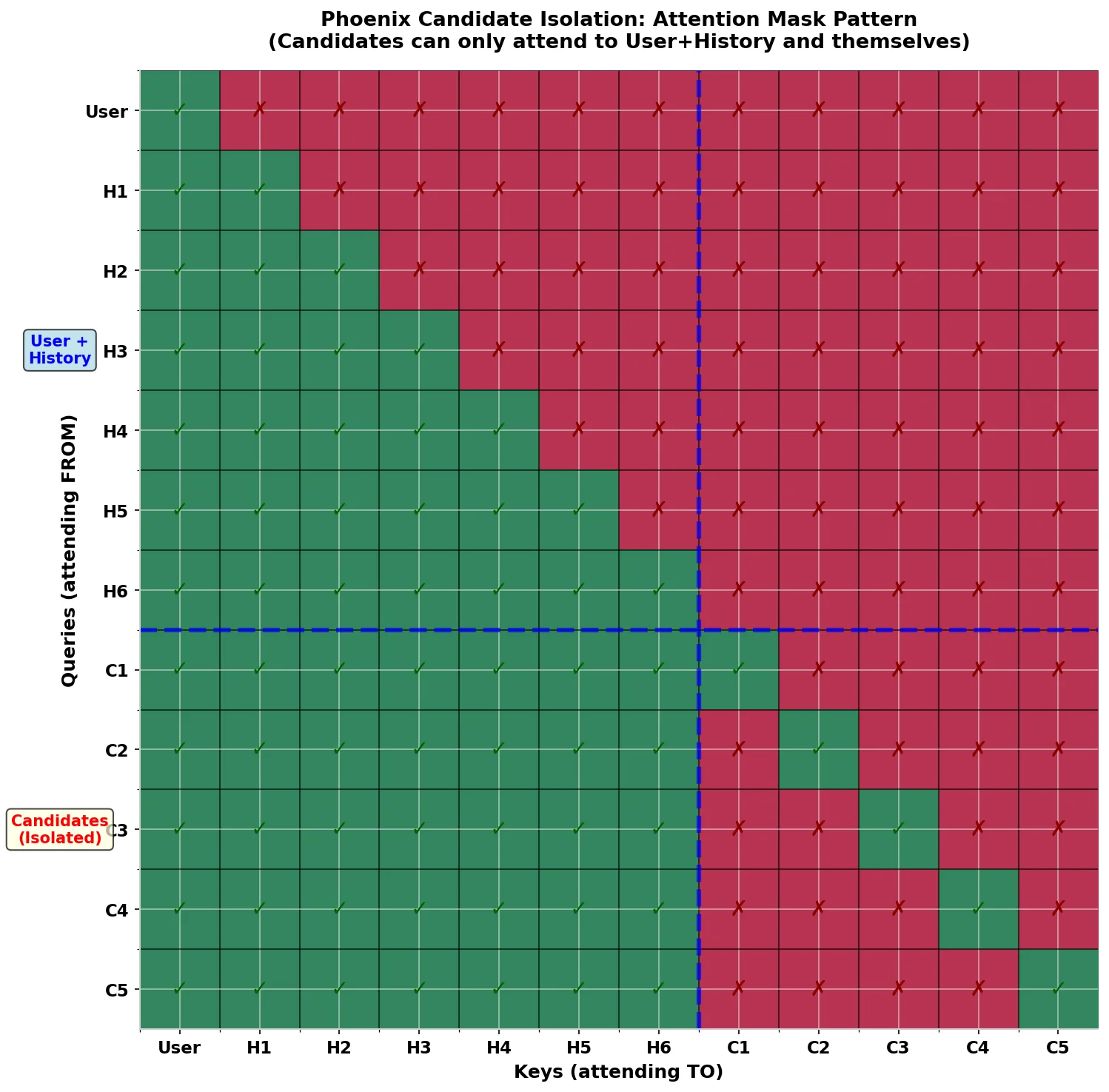
上图直观展示了候选隔离注意力掩码的结构。输入序列分为三个区域:User 前缀(1 个位置)、History(S 个位置,用户的近期互动历史)和 Candidates(C 个位置,待排序的候选帖子)。掩码规则如下:User 和 History 区域内部使用标准的因果注意力;所有 Candidates 都可以 attend 到 User 和 History(获取用户上下文);但 Candidates 之间 只能自 attend(仅对角线为 1),不能互相 attend。这一设计带来了四个关键优势:分数一致性——同一候选在不同批次中获得相同分数;可缓存性——候选分数可离线预计算和缓存;可扩展性——候选可并行独立评分,无交叉依赖;可解释性——分数反映真实的用户-候选相关性,无批次效应干扰。
2.3 多动作预测:15 维互动概率空间
与预测单一 “相关性分数” 的传统方法不同,Phoenix 的排序模型同时预测 15 种不同互动类型的概率,输出维度为 [B, num_candidates, num_actions]。这种多任务学习的方法使模型能够更全面地理解用户对内容的多维偏好。
| 动作类别 | 具体动作 | 情感极性 | 预估权重 |
|---|---|---|---|
| 正向互动 | P(favorite) — 点赞 | 正 | ~1.0x |
| 正向互动 | P(reply) — 回复 | 正 | ~1.0x |
| 正向互动 | P(repost) — 转发 | 正 | ~1.0x |
| 正向互动 | P(quote) — 引用转发 | 正 | ~0.8x |
| 正向互动 | P(click) — 点击 | 正 | ~0.5x |
| 正向互动 | P(profile_click) — 点击用户资料 | 正 | ~0.6x |
| 正向互动 | P(video_view) — 视频观看 | 正 | ~0.7x |
| 正向互动 | P(photo_expand) — 展开图片 | 正 | ~0.4x |
| 正向互动 | P(share) — 分享 | 正 | ~1.0x |
| 正向互动 | P(dwell) — 停留时间 | 正 | ~0.8x |
| 正向互动 | P(follow_author) — 关注作者 | 正 | ~0.9x |
| 负向互动 | P(not_interested) — 不感兴趣 | 负 | ~-74x |
| 负向互动 | P(block_author) — 屏蔽作者 | 负 | ~-74x |
| 负向互动 | P(mute_author) — 静音作者 | 负 | ~-74x |
| 负向互动 | P(report) — 举报 | 负 | ~-74x |
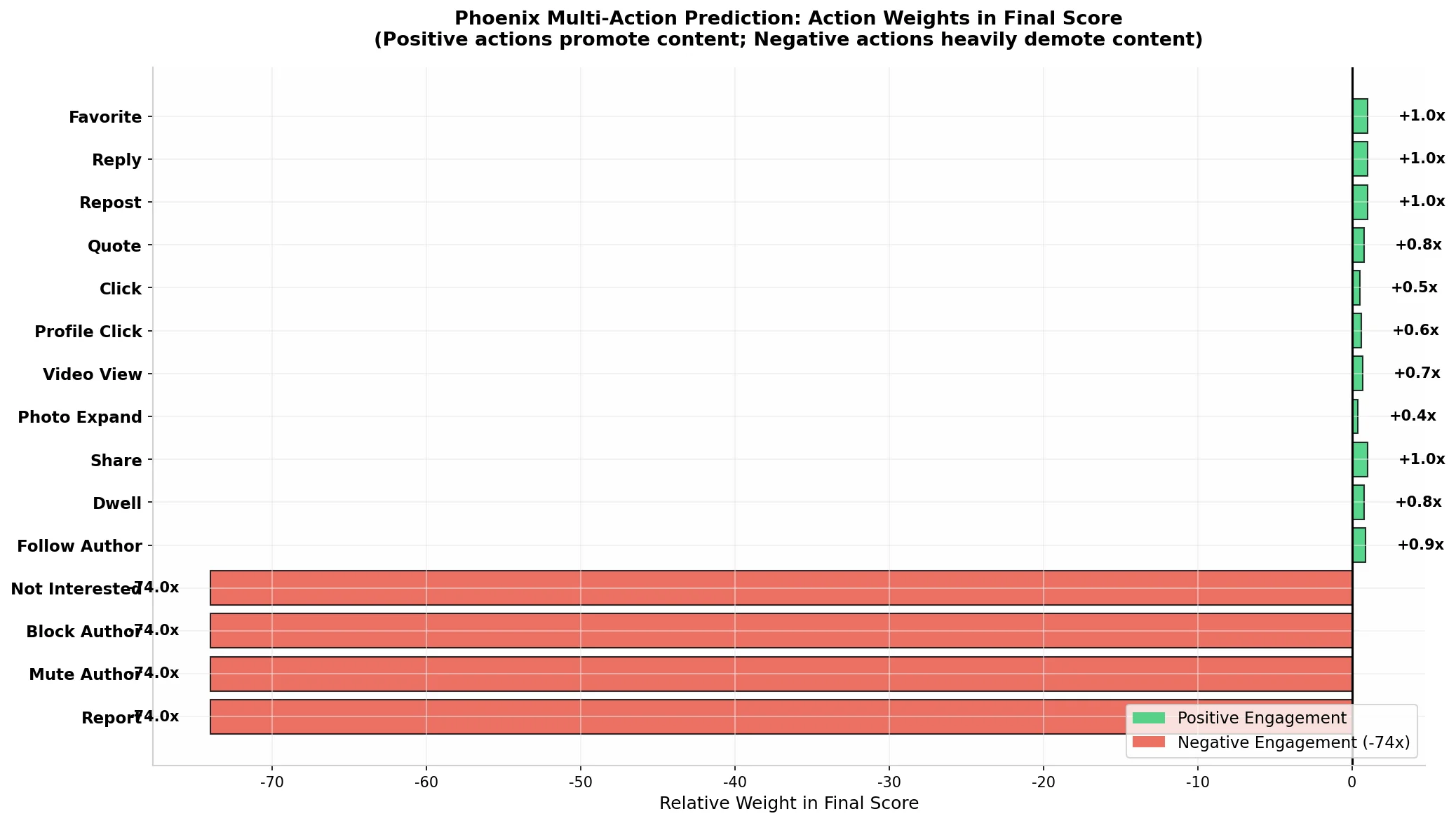
加权评分器(Weighted Scorer) 将这些多维预测组合为最终分数:Final Score = Σ (weight_i × P(action_i))。正向互动(点赞、转发、分享)具有正权重,推动内容向上排名;而负向互动(屏蔽、静音、举报、不感兴趣)具有极大的负权重(约 -74 倍),强烈压制用户可能不喜欢的内容。这种对负向信号的高度重视是 Phoenix 架构的一个显著特征——一个负向互动可以抵消数十个正向互动,这使系统能够精准地避免向用户展示可能引起反感的内容。
2.4 Hash-Based 嵌入:大规模特征的紧凑表示
Phoenix 的检索和排序模型都使用 多 hash 函数嵌入查找 来处理高基数类别特征(如用户 ID、帖子 ID、作者 ID)。与传统的大型嵌入表(vocabulary size × embedding_dim)不同,hash 嵌入通过多个独立的 hash 函数将高基数 ID 映射到低维嵌入空间,并在查找时对多个 hash 桶的嵌入进行组合。这种方法的优势在于:内存效率——无需存储完整的词汇表嵌入表,大幅减少模型内存占用;处理冷启动——对于未在训练集中出现的 ID,hash 函数仍会产生合理的嵌入表示;训练稳定性——多个 hash 函数的组合减少了单个 hash 冲突的影响。在 Phoenix 的开源示例中,提供了包含 100 万个 hash 桶 的嵌入表(retrieval 和 ranker 各 1.4 GB),以及针对体育语料库预计算的 53.7 万个帖子的候选表示。
3. 基础设施组件:高性能、低延迟的服务架构
3.1 Home Mixer:流水线编排的中枢神经
Home Mixer 是整个推荐系统的 编排层(Orchestration Layer),负责将 Phoenix 的 ML 能力与系统的其他组件协调起来,组装最终的 For You feed。它基于 candidate-pipeline 框架构建,将推荐过程抽象为多个可组合的阶段,每个阶段由实现了特定 trait 的组件处理。Home Mixer 的核心是一个 gRPC 服务(ScoredPostsService),接收用户请求后按照预定义的顺序执行流水线阶段。该组件使用 Rust 编写,充分利用了 Rust 的异步运行时(likely Tokio)来实现高并发请求处理。从代码结构来看,Home Mixer 包含以下关键模块:sources/(定义候选来源,如 Thunder 和 Phoenix Retrieval)、candidate_hydrators/(候选特征补充)、filters/(候选过滤逻辑)、scorers/(评分逻辑,包括 Phoenix ML Scorer)、selectors/(排序和选择)、query_hydrators/(查询上下文补充)以及 side_effects/(异步副作用,如缓存和日志记录)。
这种模块化的 trait-based 设计使得系统具有极高的可扩展性——工程师可以轻松添加新的候选来源、新的评分器或新的过滤器,而无需修改现有的流水线逻辑。例如,如果要添加一个新的 “趋势话题” 候选来源,只需要实现 Source trait 并将其注册到流水线中即可。同样,要实验一个新的评分策略,只需实现 Scorer trait 并在配置中启用。这种 “可组合流水线架构” 是 x-algorithm 的核心工程哲学之一。
3.2 Thunder:亚毫秒级 In-Network 内容存储
Thunder 是 X 推荐系统的 in-network 内容服务层,专门负责存储和提供用户关注账户发布的近期帖子。与需要从大型数据库中查询的 out-of-network 内容不同,Thunder 将所有关注账户的帖子维护在内存中,实现了 亚毫秒级的查找延迟。Thunder 的核心架构包括:Kafka 消费管道——Thunder 消费来自 Kafka 的帖子创建/删除事件流,实时更新内存中的数据存储;分层存储结构——按用户维护独立的存储区,分别存储原始帖子、回复/转发帖子和视频帖子,便于按类型快速检索;自动过期修剪——超过保留期的帖子自动从内存中移除,控制内存使用量。Thunder 使用 Rust 编写,这是实现极低延迟内存操作的理想选择。从代码结构来看,Thunder 包含 kafka/ 目录(Kafka 消费者实现)、posts/ 目录(帖子数据结构和存储逻辑)、thunder_service.rs(gRPC 服务接口)和 deserializer.rs(帖子反序列化逻辑)。对于 X 平台而言,Thunder 的高性能至关重要——in-network 内容通常占据用户 feed 的相当比例,且用户期望看到关注账户的最新帖子具有极低的延迟。
3.3 Candidate Pipeline:可组合的推荐框架
candidate-pipeline 是 x-algorithm 的 通用推荐流水线框架,定义了一套 trait 接口,用于构建模块化的推荐系统。该框架的核心设计目标是将流水线的执行和监控逻辑与业务逻辑分离,使工程师能够专注于实现具体的推荐策略,而无需关心底层的并发执行、错误处理和度量收集。
| Trait | 核心方法 | 功能描述 | 并发模式 |
|---|---|---|---|
Source<Q, C> |
source(&self, query: &Q) -> Result<Vec<C>, String> |
从数据源获取候选列表 | 并行执行 |
Hydrator<Q, C> |
hydrate(&self, query: &Q, candidate: &mut C) |
为候选补充额外特征 | 并行执行 |
Filter<Q, C> |
filter(&self, query: &Q, candidate: &C) -> bool |
判断是否应移除候选 | 串行执行 |
Scorer<Q, C> |
score(&self, query: &Q, candidate: &mut C) |
计算候选的分数 | 串行执行 |
Selector<Q, C> |
select(&self, candidates: &mut [C]) -> SelectResult<C> |
排序并选取 Top K | 串行执行 |
SideEffect<Q, C> |
run(&self, input: SideEffectInput<Q, C>) |
执行异步副作用 | 异步执行 |
Source trait 的实现示例展示了框架的设计哲学:每个 Source 必须实现 source() 方法返回候选列表,而 run() 包装方法由框架提供,自动添加日志记录、性能统计(通过 xai_stats_macro::receive_stats 属性宏)和分布式追踪(通过 tracing::instrument 属性宏)。这种设计使得每个组件自动获得可观测性支持,而无需开发者在业务逻辑中硬编码监控代码。框架还执行 sources 和 hydrators 的 并行执行 以优化延迟——多个候选来源可以并发获取,多个 hydrator 也可以并发 enriching 候选。
4. 关键设计决策:工程与算法的深度权衡
4.1 消除手工特征工程:纯 ML 驱动的范式转变
x-algorithm 最引人注目的设计决策之一是 完全消除了手工设计的特征工程。在传统的推荐系统中,工程师通常需要手动设计和维护大量特征——如用户的互动计数、帖子的热度分数、时间衰减因子、作者权威性指标等。这些手工特征虽然直观可解释,但存在显著的维护负担和扩展性限制。Phoenix 架构将这一责任完全转移给了 Grok-based Transformer 模型。模型直接从原始的用户互动序列中学习相关性判断,自动发现哪些信号组合最能预测用户的未来行为。这一 “无特征工程” 方法的哲学基础是:Transformer 的注意力机制本身具有强大的特征提取能力,能够从原始输入中自动学习到层次化的表示。对于推荐系统而言,用户的互动历史(点赞了帖子 A、回复了帖子 B、转发了帖子 C)本身就是最丰富的特征信号,Transformer 可以通过自注意力机制捕捉这些互动之间的复杂模式(如 “用户通常在点赞科技类帖子后,会回复相关的讨论帖”)。这种设计显著降低了数据管道的复杂性——不再需要维护复杂的特征生成和回填 pipeline,也不再需要处理特征版本兼容性问题。然而,这一方法也带来了新的挑战:模型可解释性降低、对训练数据质量和规模的依赖增加、以及 debug 难度上升。
4.2 候选隔离的工程价值:从一致性到可扩展性
候选隔离(Candidate Isolation)不仅是 Phoenix 的算法创新,更是一项具有深远工程影响的设计决策。在工业级推荐系统中,排序阶段通常需要处理数百到数千个候选,每个候选都需要通过复杂的神经网络进行推理评分。如果没有候选隔离,每次批次的组成变化都会导致分数变化,这使得以下优化手段无法实现:分数缓存——无法缓存热门候选的预计算分数,每次请求都需要重新推理;增量更新——当新候选加入时,需要重新计算整个批次的所有分数;A/B 测试可靠性——分数的批次依赖性使得实验结果难以解释;离线预计算——无法在大批量上离线计算候选分数用于在线快速查找。候选隔离通过确保每个候选的分数仅依赖于用户上下文(User + History)而不依赖于其他候选,从根本上解决了这些问题。在实际工程中,这意味着 Phoenix 可以:对热门候选进行积极的分数缓存,显著减少 ML 推理负载;支持候选的增量加入和移除,无需重新计算整个批次;进行更可靠的模型 A/B 测试,因为分数不受批次组成的影响。这些工程优势使得 Phoenix 能够在 X 平台的巨大流量规模下(日处理超过 1 亿条帖子)保持低延迟和高吞吐量。
4.3 可组合架构:模块化与可扩展性的平衡
candidate-pipeline 框架的可组合架构代表了现代推荐系统工程实践的最佳范式。通过将推荐流程分解为 Source、Hydrator、Filter、Scorer、Selector 和 SideEffect 六个核心抽象,系统实现了业务逻辑与执行框架的完全分离。这种架构的优势体现在多个层面:实验敏捷性——新的推荐策略可以通过组合现有组件快速实现,无需修改核心流水线代码;渐进式部署——新组件可以在小流量下进行 A/B 测试,验证效果后再全量上线;故障隔离——单个组件的失败不会导致整个流水线崩溃,框架提供了优雅的错误处理机制;跨团队并行开发——不同团队可以独立开发和维护各自的组件(如 ML 团队负责 Scorer,内容安全团队负责 Filter),通过标准接口集成。从 candidate_pipeline.rs 的代码实现来看,框架使用了 Rust 的 trait 系统和异步运行时来实现这些目标。流水线执行器负责调度和协调各个阶段的执行顺序,处理阶段间的依赖关系,并收集每个阶段的性能指标。这种关注点分离使得系统的复杂性得到有效管理——每个组件只需关注自身的业务逻辑,而执行、监控和错误处理由框架统一处理。
4.4 多动作预测 vs 单分数预测:精细化的用户建模
Phoenix 的多动作预测设计(同时预测 15 种互动类型的概率)代表了推荐系统建模方法的精细化演进。传统推荐系统通常预测单一的 “相关性分数” 或 “点击概率”,这种简化虽然降低了模型复杂度,但损失了用户行为的多维信息。多动作预测的核心优势在于:细粒度的用户偏好建模——不同用户对不同类型的内容有不同的互动模式。例如,某些用户倾向于 “潜水”(高 dwell 时间但低互动),而另一些用户则喜欢积极讨论(高 reply 率)。通过分别预测这些动作的概率,模型可以更好地匹配内容与用户的互动风格;内容质量的多维评估——一篇高质量的新闻文章可能获得大量 dwell 和 share,但 reply 较少;而一段争议性话题可能获得大量 reply 和 quote,但 report 也较多。多维预测使系统能够区分这些不同的内容质量模式;负向信号的显式建模——通过显式预测 not_interested、block、mute 和 report 的概率,系统可以主动避免推荐可能引起用户反感的内容,而不仅仅是被动地优化正向互动。加权评分器将这些多维预测组合为最终分数时,采用了非对称的权重策略——负向信号的权重(约 -74 倍)远大于正向信号的权重(约 1 倍)。这种设计反映了推荐系统的一个核心原则:避免错误推荐的成本远高于错过一个好推荐的成本。一个令用户厌烦的推荐可能导致用户流失,而少看一个有趣的帖子只是轻微的体验损失。
5. 行业对比与历史背景
5.1 2023 年 vs 2026 年:从 “透明度戏剧” 到生产级开源
X(Twitter)在推荐算法开源方面经历了两次截然不同的尝试,其对比揭示了工业界在算法透明度方面的演进轨迹。2023 年 3 月的首次开源 发布在 GitHub 上的 twitter/the-algorithm 仓库虽然引起了巨大轰动,但很快被批评为 “透明度戏剧”(transparency theater)。主要问题包括:代码不完整——发布的是 “部分” 代码,不包括所有关键组件;与实际生产系统不一致——开源代码与生产环境运行的代码存在差异;缺乏文档——代码几乎没有注释或架构说明;更新停滞——发布后不久就停止更新,代码逐渐与实际系统脱节。Elon Musk 当时承认:“提供代码透明度一开始会令人尴尬,但最终会导致推荐质量的快速改进”。2026 年 1 月的 Phoenix 开源 则代表了根本性的改变:完整的生产系统——开源的是实际在生产环境中运行的系统,发布当天即上线;全面的文档——提供了详细的 README、架构图和组件说明;定期更新承诺——承诺每四周推送更新并附带开发者说明;Apache 2.0 许可证——允许商业使用和修改。这种 “发布即部署” 的策略消除了 2023 年发布中的可信度缺口,使开发者和研究人员能够验证实际运行的代码。
| 对比维度 | 2023 年首次开源 | 2026 年 Phoenix 开源 |
|---|---|---|
| 代码完整性 | 部分组件 | 完整生产系统 |
| 与实际系统一致性 | 存在差异 | 发布即部署 |
| 架构基础 | 手工规则 + 启发式 | Grok Transformer ML |
| 文档质量 | 几乎无文档 | 详细架构图和说明 |
| 更新频率 | 停止更新 | 每四周定期更新 |
| 许可证 | 未明确 | Apache 2.0 |
| 社区 stars | ~60k(初期) | ~20.8k(持续增长) |
| 行业评价 | “透明度戏剧” | “行业标杆” |
5.2 与其他社交平台的透明度对比
在算法透明度方面,X 的 Phoenix 开源在主流社交平台中处于领先地位。Meta(Facebook/Instagram)——从未开源其推荐算法,仅通过博客文章和学术论文披露部分技术细节;其算法被认为是业界最复杂的之一,但完全封闭。TikTok——“For You” 页面算法被认为是其核心商业机密,从未公开代码;仅通过一般性的创作者指南说明推荐原则。YouTube——Google 通过学术论文(如 Deep Neural Networks for YouTube Recommendations)披露了部分技术,但从未开源生产代码。Snapchat——完全封闭的算法,几乎无技术披露。X 的 Phoenix 开源因此成为 首个由主流社交平台完全开源的生产级推荐系统。这种透明度水平在监管层面也具有重要意义——欧盟数字服务法案(DSA)要求大型平台提供算法透明度,X 的开源发布可以被视为对这一监管压力的积极响应。开源还使研究人员能够独立审计算法,验证关于偏见、压制或放大特定内容的声称,而不仅仅依赖于平台的自我报告。
5.3 Grok 技术栈的跨界应用:从 LLM 到推荐系统
Phoenix 架构的一个独特之处在于其直接使用了 xAI 的 Grok 大语言模型技术栈。Grok-1 是 xAI 于 2024 年 3 月开源的 3140 亿参数混合专家(MoE)模型,采用 8 个专家网络、每 token 激活 2 个专家的架构。其核心技术规格包括:64 层 Transformer、48 个查询注意力头、8 个键/值注意力头、6,144 维嵌入、SentencePiece 分词器(131,072 个 token)、RoPE(旋转位置编码)以及 8,192 token 的最大上下文长度。Phoenix 的 Transformer 实现直接移植自 Grok-1 的开源代码,保留了其核心架构特征(如分组查询注意力、RMSNorm 层归一化、RoPE 位置编码等),但进行了以下关键适配:输入嵌入层改造——从文本 token 嵌入改为推荐系统专用的 hash 嵌入,处理用户 ID、帖子 ID、作者 ID 等类别特征;注意力掩码定制——实现了候选隔离掩码 make_recsys_attn_mask,替代了标准的因果掩码;输出头扩展——从单一的语言建模头扩展为 15 个独立的动作预测头,每个头预测一种互动类型的概率;序列结构重定义——输入序列从纯文本 token 序列改为结构化的 [User, History_1, ..., History_N, Candidate_1, ..., Candidate_M] 格式。这种从 LLM 到推荐系统的技术跨界体现了基础模型(Foundation Model)思想的延伸——Grok 的 Transformer 架构作为一种通用的序列建模能力,可以通过适度的适配应用于不同的领域任务。这也是 xAI 将 Grok 技术栈深度集成到 X 平台基础设施的一个例证,两个公司共享的不只是所有权,还有基础技术栈。
6. 对开发者和内容创作者的实践启示
6.1 对开发者的技术参考价值
x-algorithm 的开源为推荐系统领域的开发者和研究人员提供了丰富的学习资源和技术参考。架构模式参考:双塔检索 + Transformer 排序的两阶段架构是当前大规模推荐系统的最佳实践,x-algorithm 提供了这一模式的完整生产级实现。特别是候选隔离注意力掩码的设计,为解决排序阶段的可扩展性问题提供了创新思路。可组合流水线框架:candidate-pipeline 的 trait-based 设计展示了如何用 Rust 的类型系统构建模块化、可扩展的推荐流水线。这一模式可以借鉴到其他语言和场景中。ML 工程实践:Phoenix 的代码展示了如何将大型 Transformer 模型部署到高吞吐、低延迟的生产环境中,包括模型导出(model_params.npz)、嵌入表管理(embedding_tables.npz)和配置管理(config.json)等方面的实践。端到端 ML 范式:从手工特征工程到纯 ML 驱动的转变提供了宝贵的迁移经验,包括如何处理训练数据构建、模型调试和在线/离线一致性等挑战。
6.2 对内容创作者的算法洞察
对于 X 平台的内容创作者而言,开源代码提供了前所未有的算法洞察,帮助优化内容策略以获得更多的 organic reach。互动质量远比数量重要:算法预测 15 种不同的互动类型,并给予它们不同的权重。Reply、Repost 和 Share 等高参与度动作的权重高于被动的 Like。创作者应设计能够引发讨论和转发的内容,而非仅仅追求点赞数。负向信号具有毁灭性影响:Not Interested、Block、Mute 和 Report 的权重约为 -74 倍,意味着一个负向互动可以抵消数十个正向互动。创作者应避免发布可能引起争议或反感的内容。停留时间(Dwell Time)是隐藏的重要信号:算法显式预测 dwell 动作的概率,用户在帖子上停留的时间越长,算法越倾向于推荐该内容。这强调了创作需要用户 “停下来阅读” 的内容的重要性——使用引人入胜的开头、合理的段落分隔和叙事弧。外部链接受到显著压制:含外部链接的帖子通常会遭受 30-50% 甚至更高的触达惩罚。策略上应将外部链接放在回复中而非主帖,或将核心内容直接发布在 X 平台上。作者多样性限制:Author Diversity Scorer 会降低来自同一作者的多个帖子的分数,以确保 feed 的多样性。这意味着即使是热门创作者,其内容在单个用户的 feed 中也会受到数量限制。
7. 局限性与未解问题
7.1 未开源的部分
尽管 x-algorithm 开源了核心推荐逻辑,但以下关键组件仍保持封闭:具体的权重常数——虽然开源了 Weighted Scorer 的架构,但各个动作类型的具体权重值在生产代码中被编辑(redacted),开发者无法得知 P(favorite) 与 P(reply) 之间的确切权重比例。训练数据和训练代码——开源了模型架构和推理代码,但未包括训练数据集、训练流程和损失函数实现。用户画像数据——Query Hydration 阶段获取的用户特征(如 “用户偏好” 的具体表示)未完全公开。广告推荐逻辑——虽然 Musk 承诺开源 “所有用于确定向用户推荐哪些有机和广告帖子的代码”,但广告排序的具体商业逻辑可能仍有所保留。内容审核模型——VFFilter 用于移除删除/垃圾/暴力/血腥内容,但其背后的内容审核模型未开源。实时基础设施——Thunder 的内存存储逻辑开源了,但底层的 Kafka 集群配置、数据复制策略和故障恢复机制未公开。
7.2 技术挑战与未来方向
x-algorithm 的当前架构仍面临若干技术挑战:冷启动问题——虽然 hash 嵌入对未见过 ID 有一定处理能力,但新用户和新帖子的推荐质量仍可能不如成熟用户和热门帖子。序列长度限制——Transformer 的上下文窗口有限,无法捕捉用户的完整历史互动,只能依赖近期的互动序列。计算成本——虽然 MoE 架构通过稀疏激活降低了推理成本,但 Phoenix 排序模型仍需对数百个候选进行 Transformer 前向传播,这在高流量场景下仍然是显著的计算负担。多样性与相关性的平衡——Author Diversity Scorer 通过降低重复作者的分数来增加多样性,但这可能与用户的真实偏好产生冲突(用户可能确实想看到某个喜爱作者的所有内容)。未来的发展方向可能包括:更长的上下文窗口——利用 Grok-3 支持 100 万 token 上下文的能力,捕捉更长的用户历史。多模态理解——Grok-1.5V 已支持图像和视频理解,未来 Phoenix 可能直接处理帖子中的视觉内容,而非仅依赖文本和元数据特征。强化学习优化——从监督学习(预测用户行为)转向强化学习(优化长期用户满意度),可能进一步提升推荐质量。
7.3 从代码看工程实现细节
深入分析 x-algorithm 的源代码可以揭示许多值得关注的工程实现细节。在 grok.py 中,right_anchored_rope_positions 函数实现了一种特殊的位置编码策略——右锚定 RoPE(Rotary Position Embedding)。这种策略确保最新的历史 token 始终获得固定的位置编号,无论历史序列的实际长度如何。具体实现中,history_end 位置被固定为最大历史长度,而实际历史 token 的位置根据当前历史长度动态计算:position = history_end - history_len + idx - history_start。这种设计的直觉是:用户最近的互动行为对于预测当前兴趣最为重要,通过将最新互动锚定到固定位置,模型可以更稳定地学习 “最近性” 这一重要信号。对于候选区域(idx >= history_end),所有候选共享相同的位置编码 history_end,这进一步强化了候选隔离的设计理念——候选之间不应该通过位置编码区分彼此。
recsys_model.py 中的 compute_post_age_bucket 函数展示了如何处理连续数值特征的离散化。帖子年龄(从发布到展示的时间间隔)被划分为以小时为粒度的桶(bucket),最大支持到 4,800 分钟(约 3.3 天),超出此范围的帖子归入溢出桶。这种离散化策略的优势在于:降低模型对精确数值的敏感度,使模型关注 “帖子是 2 小时前还是 5 小时前发布的” 而非 “帖子是 7,234 秒前发布的”;处理边界情况,通过特殊的 0 号桶处理时间戳缺失或异常的帖子。该函数使用 JAX 的向量化操作实现,支持在 GPU/TPU 上进行高效的批量计算,体现了 Phoenix 代码在性能优化方面的细致考虑。
在 candidate_pipeline.rs 中,流水线的执行通过 PipelineStage 枚举和 PipelineComponents 结构体进行显式建模。PipelineResult 结构体记录了每个阶段的候选数量变化(retrieved_candidates、filtered_candidates、selected_candidates),这种详细的度量收集使工程师能够精确地追踪每个组件对候选集的影响,快速定位流水线的瓶颈或异常。框架使用 futures::future::join_all 实现 Source 和 Hydrator 阶段的并行执行,并通过 xai_stats_macro::receive_stats 过程宏自动为每个组件方法添加性能统计和分布式追踪支持,这些工程细节体现了 xAI 团队在构建可观测性方面的系统性思考。
8. 结论:算法透明度的新标杆
xAI 开源的 x-algorithm 代表了社交媒体算法透明度的新标杆。通过将完整的生产级推荐系统(而非部分代码或学术原型)置于 Apache 2.0 许可证下,X 平台为行业树立了一个前所未有的透明度标准。这一发布的深远意义体现在多个层面:技术层面,Phoenix 架构展示了如何将大型 Transformer 模型(源自 Grok LLM 技术栈)成功应用于大规模推荐系统,特别是候选隔离注意力掩码的设计为解决排序阶段的可扩展性问题提供了创新思路。工程层面,candidate-pipeline 的可组合流水线框架和 Rust + Python 的分层技术栈策略为构建高吞吐、低延迟的推荐服务提供了可借鉴的工程实践。行业层面,在 Meta、TikTok、YouTube 等平台完全封闭其算法的背景下,X 的开源发布为算法透明度和可审计性设立了新的基准,可能推动整个行业向更开放的方向发展。社会层面,开源使独立研究人员能够验证关于算法偏见、内容放大和信息压制的声称,为公共讨论提供了基于代码证据而非推测的基础。当然,x-algorithm 的开源并非完美无缺——具体的权重常数、训练数据和部分基础设施仍保持封闭,系统的实际运行还依赖于大量未开源的周边组件。尽管如此,这次发布仍然是推荐系统领域最具影响力的开源事件之一,其价值不仅在于具体的代码实现,更在于它所代表的 “发布即部署” 的透明承诺——每四周的定期更新将使这一透明度保持持续和可验证。对于推荐系统从业者、研究人员和内容创作者而言,x-algorithm 提供了宝贵的学习资源和实践洞察,其设计理念和工程决策将在未来数年内持续影响推荐系统领域的发展走向。
参考文献
- [^1^] xAI. (2026). x-algorithm: Algorithm powering the For You feed on X. GitHub Repository. https://github.com/xai-org/x-algorithm
- [^2^] xAI. (2026). Phoenix: Recommendation System. x-algorithm/phoenix/README.md. https://github.com/xai-org/x-algorithm/tree/main/phoenix
- [^8^] xAI. (2026). grok.py: Transformer implementation for recommendation. x-algorithm/phoenix/grok.py. https://github.com/xai-org/x-algorithm/blob/main/phoenix/grok.py
- [^10^] xAI. (2026). source.rs: Source trait definition. x-algorithm/candidate-pipeline/source.rs. https://github.com/xai-org/x-algorithm/blob/main/candidate-pipeline/source.rs
- [^9^] xAI. (2026). candidate_pipeline.rs: Pipeline execution framework. x-algorithm/candidate-pipeline/candidate_pipeline.rs. https://github.com/xai-org/x-algorithm/blob/main/candidate-pipeline/candidate_pipeline.rs
- [^11^] BASENOR. (2026, March 19). X Recommendation Algorithm Gets Major Update and Goes Open Source. https://www.basenor.com/blogs/news/x-recommendation-algorithm-gets-major-update-and-goes-open-source
- [^12^] TechCrunch. (2026, January 20). X open sources its algorithm while facing a transparency fine and Grok controversies. https://techcrunch.com/2026/01/20/x-open-sources-its-algorithm-while-facing-a-transparency-fine-and-grok-controversies/
- [^13^] Conbersa AI. (2026, February 8). How Does the X (Twitter) Algorithm Work in 2026? https://www.conbersa.ai/learn/what-is-twitter-algorithm
- [^16^] Mintlify. (2026, March 10). Candidate Isolation: Critical design pattern in Phoenix ranking transformer. https://mintlify.com/xai-org/x-algorithm/concepts/candidate-isolation
- [^17^] OpenTweet. (2026, April 15). 10 X Algorithm Secrets Most Creators Miss in 2026. https://opentweet.io/blog/x-algorithm-secrets-2026
- [^19^] Typefully. (2026, January 20). Everything you need to know about the X Algorithm Update [Jan 2026]. https://typefully.com/blog/x-algorithm-open-source
- [^20^] Shaped. (2025, May 9). The Two-Tower Model for Recommendation Systems: A Deep Dive. https://www.shaped.ai/blog/the-two-tower-model-for-recommendation-systems-a-deep-dive
- [^22^] xAI. (2024, March 17). Grok-1: Open-Source 314B Parameter Model. https://github.com/xai-org/grok-1
- [^24^] Systems Analysis Wiki. (2026, March 20). Grok (xAI) — Technical Features and Architecture. https://systems-analysis.ru/int/index.php?title=Grok_(xAI)
- [^29^] BASENOR. (2026, March 19). X Recommendation Algorithm Gets Major Update — Technical Analysis. https://www.basenor.com/blogs/news/x-recommendation-algorithm-gets-major-update-and-goes-open-source
- [^31^] PPC.land. (2026, January 25). X exposes algorithm secrets. https://ppc.land/x-exposes-algorithm-secrets/